
1. Introduction
Chances are, you’ve needed to persist data in your application. Whether it’s user information or a business transaction, data has become a valuable resource for web applications.
Throughout time, application development became almost inseparable from the concept of having a well-designed data model to back it up. The importance of data in the current world made for improvements in the way we create, manage and consume information.
This article serves as a discussion for the various approaches into the connection, types, paradigms and performance of accessing a database.
2. Databases and Features
2.1 Models
There are mainly three generic approaches to storing data, which depend on the type of data (structured, semi-structured or unstructured) and the business requirements. These are relational, non-relational (NoSQL) and Object-oriented databases.
2.1.1 Relational:
The oldest and most commonly used model. It uses a tabular storage in which a table represents an entity type (such as users, customers or employees), and its rows and columns representing entity instances and entity attributes, respectively.
One common use case for this type of database model is online transaction processing systems (OLTP), which are often the foundation of a business.
Relational database engine examples: Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM Db2, SQLite.
2.1.2 Non-Relational
A non-relational database, or NoSQL, is a type of database that models and stores data differently from relational databases. Instead of tables, non-relational databases model relationships between data in an alternative way.
Inside this category there are four main NoSQL database types:
- Document
- Graph
- Key-Value
- Column-Based
Common use cases for this type of database model are IOT and real-time processing.
Non-Relational database examples: MongoDB, Redis, Cassandra, HBase.
2.1.3 Object-oriented Database
An object database similarly represents data to objects in object-oriented programming. The critical components of an object-oriented database are:
- Objects. The basic building blocks for storing information.
- Classes. The schema or blueprint for an object.
- Methods. Structured behaviors of a class.
- Pointers. Access elements of a database and establish relations between objects.
Common use cases for this type of database model are scientific purposes and high-performance applications.
Object-oriented database examples: DB4o, ObjectStore, Matisse, Gemstone/S.
2.2 Location
In regards to a database’s location, it normally falls under two categories: centralized or distributed.
2.2.1 Centralized
A centralized database is stored as well as managed in a single location. The information is available through a network. The end-user has access through the network to the centralized computer, where the stored information resides.
Features:
- Data integrity. Keeping data in one location maximizes data integrity and reduces redundancy.
- End-user friendly. Data access, as well as updates, are immediate with a centralized database.
- Cost-effective. The labor, power supply, and maintenance are all reduced to a minimum.
- Data preservation. A fault-tolerant setup through disaster recovery solutions.
2.2.2 Distributed
Distributed databases store information across different physical sites. The database resides on multiple CPUs on a single site or spread out across various locations. Due to the connections between the distributed databases, the information appears as a single database to end-users.
Features:
- Location independency. The physical location of the database spreads out across multiple sites
- Query processing distribution. A complex query splits into multiple sites, which divides the tasks between different CPUs, reducing bottleneck.
- Distributed transactions. Multiple storage locations provide a distributed recovery method. Commit protocols exist in cases of numerous transactions.
- Safety & Durability. No single point of failure.
2.3 Design
The design of a database depends on its goal in the business activity. If its objective is to control the fundamental operations of a business, it is commonly referred to as an operational database or an online transaction processing system (OLTP).
If the purpose of the database is to provide a unified view of all the data available within a business, and to provide a base for creating reports or dashboards, it is commonly referred to as an analytical database (OLAP).
3. Data Access Paradigms
Data access, from an application stand-point, is the process of connecting, retrieving and inserting data into a database. Traditionally, one would query the data with raw SQL, which led to its own set of problems. Although this approach is still used, the rise of object-relational mapping (ORM) libraries have brought some simplicity and familiarity to the development landscape.
These libraries can be interpreted as an abstraction of the database access into an object-oriented programming language. To the developer it is as if he is just working with normal classes, while under the hood, the library is constructing and compiling queries.
ORM Examples: Hibernate (JAVA), Microsoft Entity Framework (.NET Framework), Django ORM (Django)
When working with object-relational mapping (ORM) frameworks, we often have to choose between one of the three available approaches to model the data structure: Model-First, Database-First, or Code-First. Related to this operation there are also three main components: The Database, the Domain Classes and the Visual Designer.
3.1 Database-First
In this approach the database is created first and then, through a designer tool/wizard, we recreate the Visual Designer, which holds the visual representation of a database and its inter-table relationships, and the Domain Classes which are the classes (in the preferred object-oriented language) that hold the abstraction to real database entities or tables.
This approach works best if there is already a database created, or the team responsible for the data layer has more experience with working with the database directly.
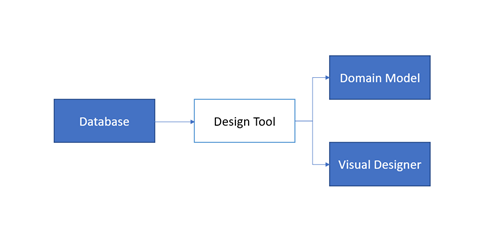
3.2 Model-First
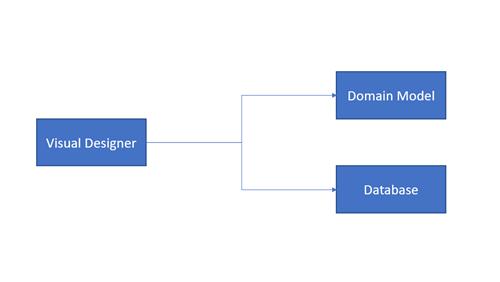
If one is not familiar with a designer model interface this approach can be confusing. But essentially, the key to understand it is to acknowledge the fact that the word “Model” here is a visual diagram built with the design tools; that diagram will then be used to autogenerate the Database SQL script and the Data Domain Classes.
This approach works best if the team is creating a new database, is familiar with the design tools, or the team doesn’t have experience with working directly with a database. Either way, apart from knowing the design tool, this approach may be suitable for beginners.
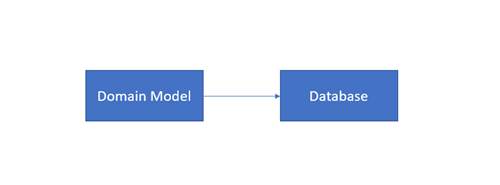
3.3 Code-First
The appeal of this approach can be easily found in its premise: Code-First approach allows the developer to define model objects using only standard classes, without the need of any design tool, XML mapping files, or cumbersome piles of autogenerated code. It is simply the generation of a database from classes. Also, the Visual Designer is not a part of this approach.
This approach is more suitable for teams creating a new database or that have knowledge in ORM programming language and conventions. This approach makes generating and changing the database at any point a simpler process.
4. Loading Paradigms
While working with a database and possibly an object-relational mapping (ORM) library, it is common to query data that is related to the base entity we are trying to access. For instance, you might want to access a specific post’s comments, or a collection of purchases from a costumer.
There are three main paradigms we can use to access an entity’s relations: eager-loading, explicit-loading and lazy-loading.
4.1 Eager-Loading
Eager-loading, at its core, loads all your needed entities at once; i.e., all your child entities will be loaded at single database call. In one round-trip the library constructs a query to fetch all the related entities you’ve set to be gathered.
This approach, of gathering all the information immediately, can be very efficient as only one round-trip to the database is needed. It can also set the grounds for a cartesian explosion, which is a performance issue caused by a large quantity of related entities being fetched.
4.2 Explicit-Loading
Explicit-loading is an approach of gathering the information about an entity’s relations on demand, as you need them. Instead of fetching all the information in one go, because sometimes you don’t need it in memory yet, you explicitly fetch the desired relations whenever you might need them.
Explicit-loading lets you defer querying for relations at a cost of more round-trips to the database.
4.3 Lazy-Loading
Lazy-loading is an approach very close to the explicit paradigm. Basically, it queries an entity’s relations under-the-hood, when we first reference them, without the need for an explicit call. Think of it as an automated explicit-loading. This approach is the less cumbersome for the programmer, but can unexpectedly create major inefficiencies if not used correctly ang thoughtfully.
5. Performance
With evolution of technology in general, came a world of instantaneous connections. Immediate responses, low-latency and broad access are not a luxury in today’s world, but a necessity.
Performance is mandatory in a fast-paced world, and even though it is relative (depending on the business, different metrics measure performance) and every case needs to be studied and analyzed, below there are some topics that might help to increase performance in data access.
5.1 Non-Tracking Queries
Some ORMs provide capabilities of tracking changes, if the purpose of a query is just to present or list values, disabling change tracking might be helpful.
5.2 Split queries
Depending on the ORM and/or the Database provider this technique can be advantageous for large complex queries. While some providers don’t allow for automated split queries from an ORM, this technique can be used still “manually” by segmenting calls.
The objective of this technique is to prevent unnecessary duplication when fetching relations by segmenting complex queries into various simpler queries for the same result. One major drawback of this approach is consistency and extra round-trips to the database. As the complex queries are segmented, the DBMS (Database Management System) does not guarantee consistency between calls, furthermore, there are more calls to this system as opposed to one single complex query.
5.3 Stored Procedures
One of the great ways to improve performance at almost no cost is stored procedures. Stored procedures are prepared SQL statements that can be saved and reused. It can consume parameters and also return the same results as a normal query; the main difference is that is caches the execution plans.
This technique improves performance tremendously in larger complex queries, but its effects can also be noticeable on simpler queries. The usual scenarios for such technique are: repeating, complex or heavy queries.
5.4 Views
Views are seen as virtual tables; a view is a persisted SQL select statement. In plain words, it is a saved result that you can query against, just as any other table. While stored procedures are more frequently utilized for heavy workloads, views are used to facilitate data retrieval.
Usual scenario for the creation of views are complex queries with many relations. A view can materialize a complex series of joins into a single table.
5.5 Indexing
Indexing is a technique that uses a data structure that improves the speed of data retrieval operations on a database table.
An Index functions as a book index does, it is a series of orientations on where to retrieve data. There are various implementations of indexing each with its unique cases, but generally the architecture falls under two categories:
Clustered
The creation of a clustered index is process that produces a data structure that physically alters the order of a table (by a column or multiple columns) and bases its indexing on that organized table. Because it alters the physical order of the table it can only exist one for it.
Non-clustered
Opposed to a clustered index, a non-clustered index does not affect the physical order of a table and, therefore, can exist a multitude of them. Similarly, to a clustered index, it created a data structure so that navigation to retrieve information is optimized.
6. Conclusion
This article serves as a discussion around the concepts regarding a database, its access and topics related to efficiency. It is intended to provide general, technology agnostic, notions and tips for a better understanding of this important layer in an application environment.
As the world evolves and revolves around data, it is mandatory to refresh the view towards data persistence, access and transport, as well as efficiency and security.
Most of the times data access does not reach its maximum potential (of performance, availability and security) because its often overlooked. Being the backbone of most applications, it sets the immediate standard for efficiency, and by understanding it better, and applying proper techniques, it can have tremendously impact on general user experience.
#Enterprises #Users #Dataaccess #Database #Web