
1. Introdução
É provável que tenha de manter dados na sua aplicação. Quer se trate de informações de utilizadores ou de uma transação comercial, os dados tornaram-se um recurso valioso para aplicações web.
Ao longo do tempo, o desenvolvimento de aplicações tornou-se quase inseparável do conceito de ter um modelo de dados bem desenhado para o apoiar. A importância dos dados no mundo atual trouxe mehorias na forma como criamos, gerimos e consumimos informação.
Este artigo serve como uma discussão para as várias abordagens na conexão, tipos, paradigmas e desempenho de acesso a uma base de dados.
2. Bases de dados e recursos
2.1 Modelos
Há principalmente três abordagens genéricas para armazenar , que dependem do tipo de dados (estruturado, semi-estruturado ou desestruturado) e os requisitos de negócio. Estes são relacional, não relacional (NoSQL) e data databases Orientado para objetos.
2.1.1 Relacional:
O modelo mais antigo e mais utilizado. Usa um armazenamento tabular em que uma tabela representa um tipo de entidade (tais como utilizadores, clientes ou funcionários), e as suas linhas e colunas representam instâncias de entidades e atributos de entidade, respetivamente.
Um caso de uso comum para este tipo de modelo de base de dados é online transaction processing systems (OLTP – Sistemas de processamento de transações online), que são muitas vezes a base do negócio.
Exemplos de Base de dados Relacionais: Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM Db2, SQLite.
2.1.2 Não Relacional
Uma base de dados não relacional, ou NoSQL, é um tipo de base de dados que modela e armazena dados de maneira diferente bases de dados Relacional. Em vez de tabelas, bases de dados não relacionais modelam relações entre dados de uma forma alternativa.
Dentro desta categoria há quatro principais NoSQL tipos de bases de dados:
- Documento
- Gráfico
- Valor Chave
- Baseado em Colunas
Casos de uso comum para este tipo de modelo de base de dados são IOT e processamento em tempo real.
Exemplos de base de dados Não Relacional: MongoDB, Redis, Cassandra, HBase.
2.1.3 Base de Dados orientada para objetos
Uma base de dados de objetos representa igualmente dados para objetos em programação orientada a objetos. Os componentes críticos de uma base de dados orientada para objetos são:
- Objetos. Os blocos básicos de construção para armazenar informações.
- Classses. O esquema ou planta para um objeto.
- Métodos. Comportamentos estruturados de uma classe.
- Indicações. Aceder a elementos de uma base de dados e estabelecer relações entre objetos.
Casos de uso comum para este tipo de base de dados são fins científicos e aplicações de alto desempenho.
Exemplos de base de dados orientada para objetos: DB4o, ObjectStore, Matisse, Gemstone/S.
2.2 Localização
No que diz respeito à localização de uma base de dados, normalmente enquadra-se em duas categorias: centralizada ou distribuída.
2.2.1 Centralizada
Uma base de dados centralizada é armazenada, bem como gerido em um único local. A informação está disponível através de uma rede. O utilizador final tem acesso através da rede ao computador centralizado, onde reside a informação armazenada.
Características:
- Integridade dos dados. Manter dados num local maximiza a integridade dos dados e reduz a redundância.
- Amigável para o utilizador final. Acesso a dados, bem como atualizações, são imediatas com uma base de dados centralizada.
- Custo Benificio. O trabalho, o fornecimento de energia e a manutenção são todos reduzidos ao mínimo.
- Preservação de dados. Uma configuração tolerante a falhas através de soluções de recuperação de desastres.
2.2.2 Distribuída
Bases de dados distribuídas armazenam informações em diferentes sites físicos. O base de dados reside em vários CPUs em um único site ou espalhados por vários locais. Devido às ligações entre as bases de dados distribuídas, a informação aparece como uma única base de dados para os utilizadores finais.
Características:
- Independência de localização. A localização física da base de dados espalha-se por vários sites.
- Distribuição de processamento de consulta. Uma consulta complexa divide-se em vários sites, que divide as tarefas entre diferentes CPUs, reduzindo o “estrangulamento”.
- Operações distribuídas. Vários locais de armazenamento fornecem um método de recuperação distribuído. Protocolos de confirmação existem em casos de numerosas transações.
- Segurança e Durabilidade. Nenhum ponto de falha.
2.3 Design
O design de uma base de dados depende do seu objetivo na atividade empresarial. Se o seu objetivo é controlar as operações fundamentais de uma empresa, é normalmente referido como uma base de dados operacional ou um sistema de processamento de transações online (OLTP).
Se o propósito da base de dados é fornecer uma visão unificada de todos os dados disponíveis dentro de uma empresa, e fornecer uma base para a criação de relatórios ou dashboards, é normalmente referido como uma base de dados analítica.
3. Paradigmas de Acesso a Dados
Acesso a dados, a partir de um ponto de suporte de aplicação, é o processo de ligação, recuperação e inserção de dados numa base de dados. Tradicionalmente, iria consultar os dados com raw SQL, que levou ao seu próprio conjunto de problemas. Embora essa abordagem ainda seja usada, o surgimento de bibliotecas de mapeamento objeto-relacional (ORM) trouxe simplicidade e familiaridade ao cenário de desenvolvimento.
Estas bibliotecas podem ser interpretadas como uma abstração do acesso à base de dados numa linguagem de programação orientada a objetos. Para quem realiza o desenvolvimento é como se estivesse apenas a trabalhar com classes normais, enquanto nos bastidores a biblioteca está construindo e compilando consultas.
Exemplos ORM: Hibernate (JAVA), Microsoft Entity Framework (.NET Framework), Django ORM (Django)
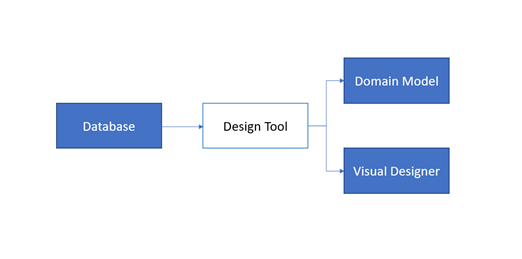
Ao trabalhar com estruturas de mapeamento objeto-relacional (ORM), muitas vezes temos de escolher entre uma das três abordagens disponíveis para modelar a estrutura de dados: Model-First, Database-First, ou Code-First. Relativamente a esta operação existem também três componentes principais: Uma Base de Dados, o Classes de Domínio e o Visual Designer.
3.1 Base de dados-Primeiro
Nesta abordagem a base de dados é criada primeiro e depois, através de uma ferramenta/assistente de design, recriamos o Visual Designer, que detém a representação visual da base de dados e as suas relações inter-tabelas, e o Classes de Domínio que são as classes (na linguagem orientada para objetos preferidos) que mantêm a abstração para entidades ou tabelas de base de dados reais.
Esta abordagem funciona melhor se já existir uma base de dados criada, ou a equipa responsável pela camada de dados tem mais experiência em trabalhar diretamente com a base de dados.
3.2 Model-First
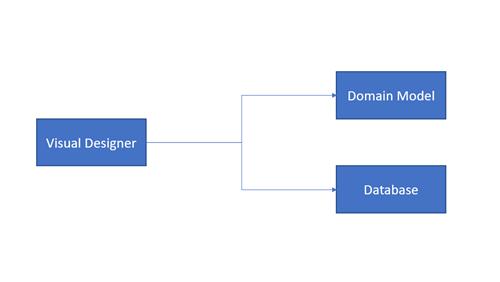
Se não estiver familiarizado com um interface de modelo de design esta abordagem pode ser confusa. Mas essencialmente, a chave para compreendê-lo é reconhecer o facto de que a palavra "Model" aqui é um diagrama visual construído com as ferramentas de design; que o diagrama será então usado para autogerar a script SQL de base de dados e a Classes de Domínio de Dados.
Esta abordagem funciona melhor se a equipa que estiver a criar uma nova base de dados, estiver familiarizada com as ferramentas de design, ou a equipa não tem experiência em trabalhar diretamente com uma base de dados. De qualquer forma, além de conhecer a ferramenta de design, esta abordagem pode ser adequada para principiantes.
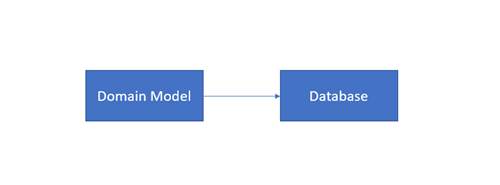
3.3 Code-First
O apelo desta abordagem pode ser facilmente encontrado na sua premissa: A abordagem Code-First permite ao programador definir objetos de modelo usando apenas classes padrão, sem a necessidade de qualquer ferramenta de design, ficheiros de mapeamento XML, ou cumbersome piles de código autogerado. É simplesmente a criação de uma base de dados de classes. Além disso, o Visual Designer não faz parte desta abordagem.
Esta abordagem é mais adequada para equipas que criem uma nova base de dados ou que possuem conhecimentos em linguagem e convenções de Programação ORM. Esta abordagem torna a geração e alteração da base de dados em qualquer ponto um processo mais simples.
4. Paradigmas de Carregamento
Ao trabalhar com uma base de dados e, possivelmente, uma biblioteca de mapeamento objeto-relacional (ORM), é comum consultar dados que estejam relacionados com a entidade base a que estamos a tentar aceder. Por exemplo, você pode querer aceder a comentários de um post específico, ou uma coleção de compras de um cliente.
Existem três paradigmas principais que podemos usar para aceder às relações de uma entidade: carregamento rápido, carregamento explícito e carregamento lento.
4.1 Eager-Loading (carregamento rápido)
Carregamento rápido, no seu cerne, carrega todas as suas entidades necessárias de uma só vez; ou seja, todas as suas entidades infantis serão carregadas numa única chamada base de dados. Numa viagem de ida e volta, a biblioteca constrói uma consulta para ir buscar todas as entidades relacionadas que está a ser recolhida.
Esta abordagem, de recolher imediatamente toda a informação, pode ser muito eficiente, uma vez que apenas é necessária uma ida e volta à base de dados. Também pode definir os fundamentos para uma explosão cartesiana, que é um problema de desempenho causado por uma grande quantidade de entidades relacionadas sendo recolhidas.
4.2 Explicit-Loading (Carregamento explícito)
Carregamento explícito é uma abordagem de recolha de informação sobre as relações de uma entidade a pedido, conforme necessário. Em vez de ir buscar toda a informação de uma só vez, porque às vezes ainda não precisa dela na memória, podemos ir buscar explicitamente as relações desejadas sempre que seja necessário.
Carregamento explícito permite adiar a consulta de relações a um custo de mais viagens de ida e volta para a base de dados.
4.3 Lazy-Loading (Carregamento lento)
Carregamento lento é uma abordagem muito próxima do paradigma explícito. Basicamente, questiona as relações de uma entidade nos bastidores, quando as referenciamos pela primeira vez, sem a necessidade de uma chamada explícita. Devemos pensar nisso como carregamento explícito automatizado. Esta abordagem é a menos complicada para o programador, mas pode inesperadamente criar grandes ineficiências se não for utilizada corretamente e com atenção.
5. Desempenho
Com a evolução da tecnologia em geral, surgiu um mundo de conexões instantâneas. Respostas imediatas, baixa latência e acesso amplo não são um luxo no mundo de hoje, mas uma necessidade.
O desempenho é obrigatório num mundo acelerado, e mesmo que seja relativo (dependendo do negócio, diferentes métricas medem o desempenho) e todos os casos precisam de ser estudados e analisados, abaixo existem alguns tópicos que podem ajudar a aumentar o desempenho no acesso aos dados.
5.1 Consultas sem rastreamento
Alguns ORMs fornecem capacidades de rastreio de alterações, se o propósito de uma consulta for apenas apresentar ou listar valores, desativar o rastreio de alterações pode ser útil.
5.2 Consultas divididas
Dependendo do ORM e/ou do fornecedor de base de dados, esta técnica pode ser vantajosa para grandes consultas complexas. Embora alguns fornecedores não permitam consultas de divisão automatizadas a partir de um ORM, esta técnica pode ser usada ainda "manualmente" através de segmentação de chamadas.
O objetivo desta técnica é evitar duplicações desnecessárias ao procurar relações segmentando consultas complexas em várias consultas mais simples para o mesmo resultado. Uma grande desvantagem desta abordagem é a coerência e as viagens de ida e volta extra à base de dados. À medida que as consultas complexas são segmentadas, o DBMS (Sistema de Gestão de Bases de Dados) não garante a consistência entre chamadas, além disso, há mais chamadas para este sistema em oposição a uma única consulta complexa.
5.3 Procedimentos armazenados
Uma das grandes formas de melhorar o desempenho quase sem custo são os procedimentos armazenados. Os procedimentos armazenados são declarações SQL preparadas que podem ser guardadas e reutilizadas. Pode consumir parâmetros e também devolver os mesmos resultados que uma consulta normal; a principal diferença é que ele armazena em caches os planos de execução.
Esta técnica melhora substancialmente o desempenho em consultas complexas maiores, mas os seus efeitos também podem ser percetíveis em consultas mais simples. Os cenários habituais para tal técnica são: consultas repetidas, complexas ou pesadas.
5.4 Modos de exibição
Modos de exibição são exibidos como tabelas virtuais; uma view (vista) é uma declaração SQL selecionada persistente. Em palavras simples, é um resultado guardado que se pode consultar, assim como qualquer outra tabela. Embora os procedimentos armazenados sejam mais frequentemente utilizados para cargas de trabalho pesadas, as views são usadas para facilitar a recuperação de dados.
Cenário habitual para a criação de views são consultas complexas com muitas relações. Uma view pode materializar uma série complexa de uniões numa única tabela.
5.5 Indexação
Indexação é uma técnica que utiliza uma estrutura de dados que melhora a velocidade das operações de recuperação de dados numa tabela de base de dados.
Um Índice funciona como um índice de livro funciona, é uma série de orientações sobre onde recuperar dados. Existem várias implementações de indexação de cada um com os seus casos únicos, mas geralmente a arquitetura se enquadra em duas categorias:
Agrupado
A criação de um índice agrupado é um processo que produz uma estrutura de dados que altera fisicamente a ordem de uma tabela (por uma coluna ou várias colunas) e baseia a sua indexação naquela tabela organizada. Porque altera a ordem física da tabela só pode existir uma para ela.
Não agrupados
Em oposição a um índice agrupado, um índice não agrupado não afeta a ordem física de uma tabela e, portanto, pode existir uma multiplicidade deles. Da mesma forma, para um índice agrupado, criou uma estrutura de dados para que a navegação para recuperar informações seja otimizada.
6. Conclusão
Este artigo serve como uma discussão em torno dos conceitos relativos a uma base de dados, ao seu acesso e tópicos relacionados com a eficiência. O objetivo é fornecer informações gerais e agnósticas em termos tecnológicos, noções e dicas para uma melhor compreensão desta importante camada num ambiente de aplicação.
À medida que o mundo evolui e gira em torno dos dados, é obrigatório refrescar a visão para a persistência, acesso e transporte de dados, bem como eficiência e segurança.
A maior parte dos tempos de acesso a dados não atinge o seu potencial máximo (de desempenho, disponibilidade e segurança) porque muitas vezes é negligenciado. Sendo a espinha dorsal da maioria das aplicações, estabelece o padrão imediato de eficiência, e ao compreendê-lo melhor, e aplicando técnicas adequadas, pode ter um impacto tremendo na experiência geral do utilizador.
#Empresas #Utilizadores #Acessodados #Basedados #Web